EliteTrackr
- 800KAthletes
- 14MPerformances
- 230Countries
- 9Languages
Context
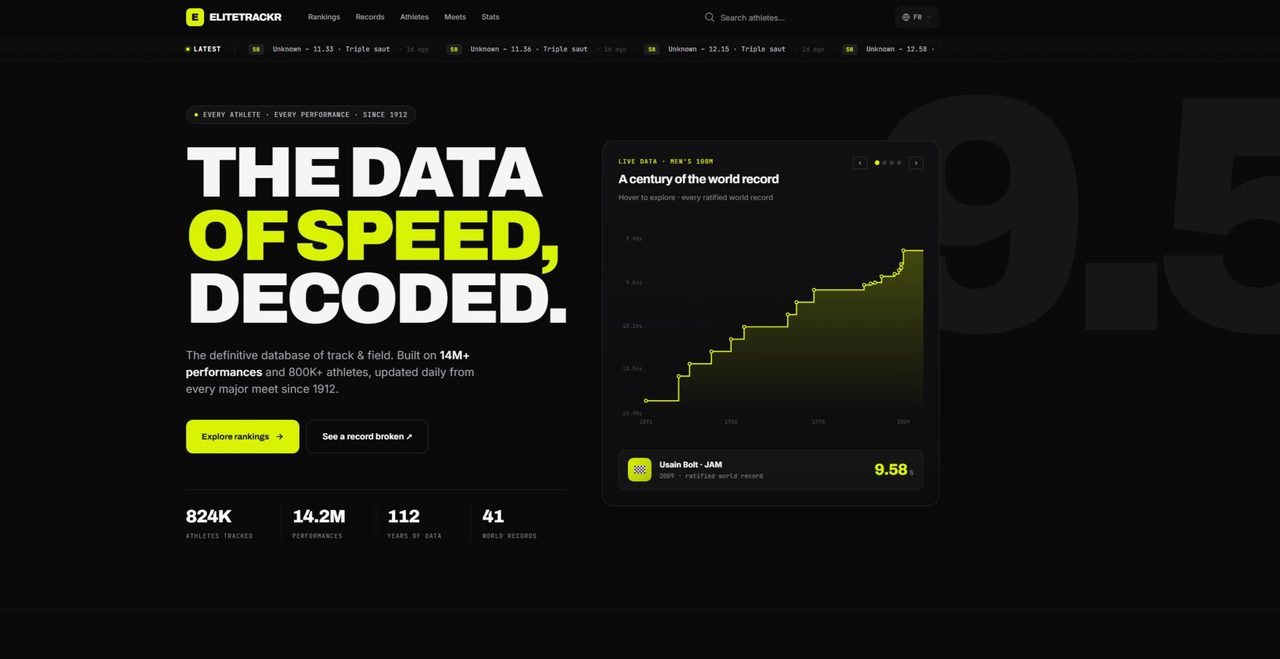
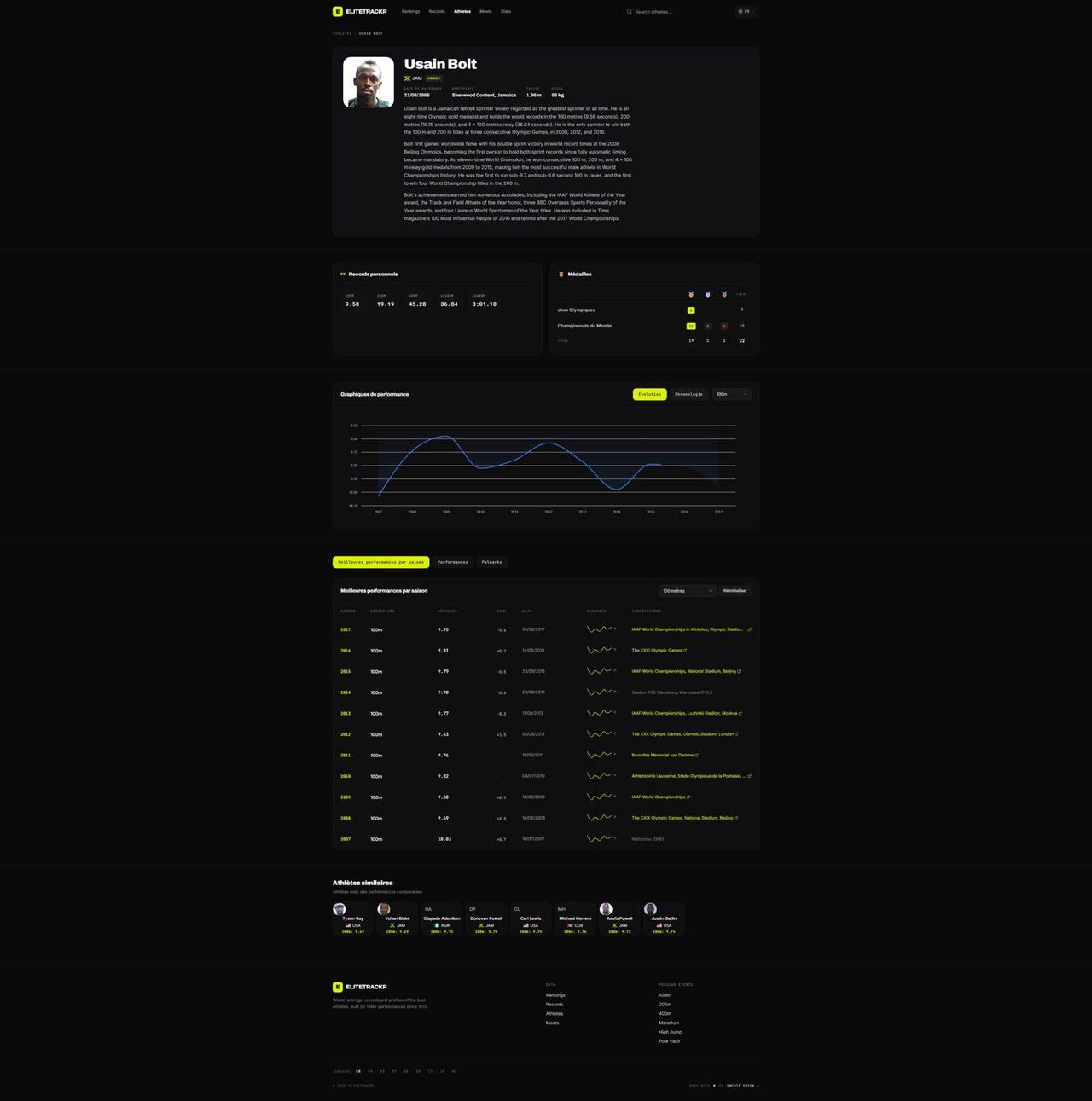
I did track and field for years. Every time I wanted to dig into a performance, compare a season, or follow an athlete's trajectory, I'd hit sites capped at the Olympics or the biggest meets — never the full picture, never the tools to tell stories with the numbers. So I built it. EliteTrackr is the ambition to become the Wikipedia of athletics: a global, multilingual reference where raw data becomes readable again — for fans, athletes, coaches.
My approach
Three things to ship alone: get the data in, make it indexable everywhere, and protect it. Each with its own constraints — from a pipeline that digests 14M performances to infrastructure that has to hold against scrapers and AI bots.
- A Python pipeline that aggregates data from several sources and consolidates it into one database: 800,000 athletes, 14 million performances, 230 countries — and growing every day.
- Nuxt SSR + i18n across 9 languages, with an indexing strategy tuned per market. No ads, no growth hacking — the quality of the data does the rest.
- Cloudflare up front to absorb bots, AI scrapers, and attacks. Redis to cache hot queries. A defensive architecture from day one.
Stack & technical choices
Full-JS to share types end-to-end between Nuxt and AdonisJS, and to ship Adonis in production (a deliberate bet). Python for the data layer: better raw performance and an unmatched data-science ecosystem. Postgres for persistence, Redis for cache, Coolify for deployment.
Outcome & takeaways
Live since January 2026. ~50 visitors/day, pure organic growth, no paid acquisition. Lighthouse 99/92/96 on desktop, 80/92/96 on mobile — on pages serving up to 14M records. All solo: design, UI/UX, front, back, devops, data, SEO. Beyond the numbers, this is the project where I found my voice — visual, tone, structure — and where I watch the database grow a little richer every day. Value compounds.